Trong bối cảnh chuyển đổi số, dữ liệu được xem là tài sản chiến lược của mọi doanh nghiệp. Tuy nhiên, giá trị thực sự của tài sản này chỉ có thể được khai phá khi nó được kết nối, hợp nhất và chuyển đổi thành những insight hữu ích cho việc ra quyết định. Thực tế tại nhiều tổ chức cho thấy, dữ liệu thường bị phân mảnh trong các hệ thống độc lập (silo), dẫn đến tình trạng thiếu nhất quán và khó khăn trong việc tổng hợp, phân tích.
Vừa qua, Lead Consulting đã triển khai thành công dự án tư vấn, triển khai tích hợp và phân tích dữ liệu cho một tổ chức lớn có hệ thống dữ liệu phức tạp. Tổ chức này đối mặt với các thách thức điển hình của các doanh nghiệp có hạ tầng công nghệ thông tin lâu đời: dữ liệu vận hành bị phân mảnh trên nhiều hệ quản trị cơ sở dữ liệu (CSDL) khác nhau, bao gồm cả Oracle, SQL Server, My SQL, v.v. và các nguồn dữ liệu dạng file rời rạc. Điều này khiến tổ chức phải đối mặt với nhiều thách thức, tiêu biểu như:
❌ Hạn chế trong việc ra quyết định dựa trên dữ liệu do báo cáo từ các nguồn thường không nhất quán, thiếu tin cậy;
❌ Tiêu tốn nguồn lực và làm chậm quy trình phân tích do phải dành phần lớn thời gian cho việc tổng hợp dữ liệu thủ công thay vì tập trung vào các nhiệm vụ có giá trị cao hơn như tìm kiếm insight và đề xuất giải pháp.
Để giải quyết bài toán này, đội ngũ chuyên gia của Lead Consulting đã phân tích và đánh giá các công nghệ tích hợp dữ liệu trên thị trường, từ đó lựa chọn ra giải pháp ETL (Extract – Transform – Load) phù hợp nhất với các yêu cầu khắt khe về độ trễ, khả năng mở rộng và chi phí.
Bài viết này chia sẻ chi tiết về bộ tiêu chí chúng tôi đã sử dụng để lựa chọn công nghệ, so sánh ưu nhược điểm của các giải pháp phổ biến, và đi sâu vào kiến trúc triển khai thực tế đã giúp khách hàng xây dựng thành công một nền tảng dữ liệu hợp nhất, đáng tin cậy.
-
Các tiêu chí lựa chọn công nghệ ETL
Để lựa chọn công nghệ ETL phù hợp, LEAD đã đưa ra 8 tiêu chí đánh giá gồm:
- Cơ chế thu thập dữ liệu (Log-based, Trigger-based, Query-based, v.v.)
- Độ trễ khi truyền tải dữ liệu (Real-time, Near real-time, Batch)
- Mức độ can thiệp vào CSDL nguồn (Tác động đến hiệu năng, yêu cầu thay đổi schema)
- Khả năng hỗ trợ đa dạng CSDL nguồn
- Khả năng hỗ trợ đa dạng CSDL đích
- Độ phức tạp khi triển khai và vận hành
- Khả năng tích hợp và mở rộng trong tương lai
- Chi phí đầu tư (License, hạ tầng, nhân sự)
-
So sánh các Giải pháp Tích hợp Dữ liệu
Dựa trên các tiêu chí trên, Lead Consulting đã phân tích và so sánh bốn giải pháp công nghệ nổi bật:
 A. Debezium & Kafka
A. Debezium & Kafka
- Cơ chế hoạt động: Hệ thống sử dụng cơ chế Change Data Capture dạng log-based, đọc trực tiếp từ redo/transaction log của CSDL nguồn. Nhờ đó, gần như không cần can thiệp vào ứng dụng hay thay đổi cấu trúc dữ liệu gốc.
- Độ trễ: Dữ liệu được đồng bộ tức thì, đạt mức cận real-time.
- Khả năng mở rộng: Hỗ trợ nhiều hệ quản trị CSDL nguồn (Oracle, SQL Server, MySQL, PostgreSQL, …) và ghi dữ liệu ra nhiều hệ CSDL đích thông qua ODBC.
- Khả năng tích hợp: Sử dụng Kafka topic làm tầng trung gian truyền tải dữ liệu, cho phép mở rộng linh hoạt và dễ dàng kết nối với các dịch vụ khác.
- Chi phí: Là giải pháp mã nguồn mở, không tốn chi phí license, phù hợp cho các dự án cần tính linh hoạt và khả năng mở rộng dài hạn.
B. SymmetricDS
- Cơ chế: Dựa trên trigger để sinh bản ghi thay đổi.
- Độ trễ: Tương đối thấp, dao động từ 1 – 5 phút.
- Ưu điểm: Hỗ trợ nhiều loại database nguồn và đích, triển khai khá đơn giản, không ảnh hưởng cơ sở dữ liệu.
- Hạn chế: Giao diện quản lý còn hạn chế; phiên bản mã nguồn mở thiếu tính năng nâng cao, bản Pro cần trả phí.
C. Apache NiFi
- Cơ chế: Định kỳ query dữ liệu theo batch.
- Độ trễ: Thường từ 1 – 5 phút, phụ thuộc tần suất polling.
- Ưu điểm: Dễ triển khai, hỗ trợ ghi và đọc dữ liệu từ nhiều nguồn khác nhau.
- Hạn chế: Yêu cầu query thường xuyên dẫn tới tăng tải cơ sở dữ liệu nguồn; độ real-time không cao.
- Chi phí: Mã nguồn mở, chi phí thấp.
D. Oracle GoldenGate
- Cơ chế: Tích hợp Change Data Capture native do Oracle phát triển, giúp đồng bộ dữ liệu với độ trễ thấp, đạt mức cận real-time.
- Hạn chế: Chỉ tối ưu cho hệ CSDL Oracle, ít linh hoạt khi cần kết nối với các hệ quản trị khác.
- Độ phức tạp: Việc triển khai và vận hành phức tạp, đòi hỏi đội ngũ kỹ thuật chuyên sâu.
- Chi phí: Yêu cầu license thương mại, chi phí cao
-
Kết quả lựa chọn
Dựa vào 6 lợi thế nổi trội trong 8 tiêu chí đánh giá, Lead Consulting đã lựa chọn Debezium & Kafka làm giải pháp trung tâm. Đây là lựa chọn tối ưu cho các môi trường doanh nghiệp phức tạp, nơi tồn tại nhiều hệ thống quản lý khác nhau cần được tích hợp và đồng bộ.
Với lựa chọn sử dụng Debezium & Kafka, giải pháp này không yêu cầu cấu hình quá phức tạp. Chỉ cần máy chủ có:
- 16 vCPU
- Từ 32 GB RAM
- 100 GB SSD trở lên
là đã có thể vận hành ổn định, đáp ứng tốt nhu cầu xử lý dữ liệu lớn.
Nhờ vậy, tổ chức vừa tiết kiệm chi phí đầu tư hạ tầng, vừa đảm bảo quy trình ETL và dashboard hoạt động hiệu quả, bền vững trong dài hạn.
-
Kiến trúc hệ thống cụ thể
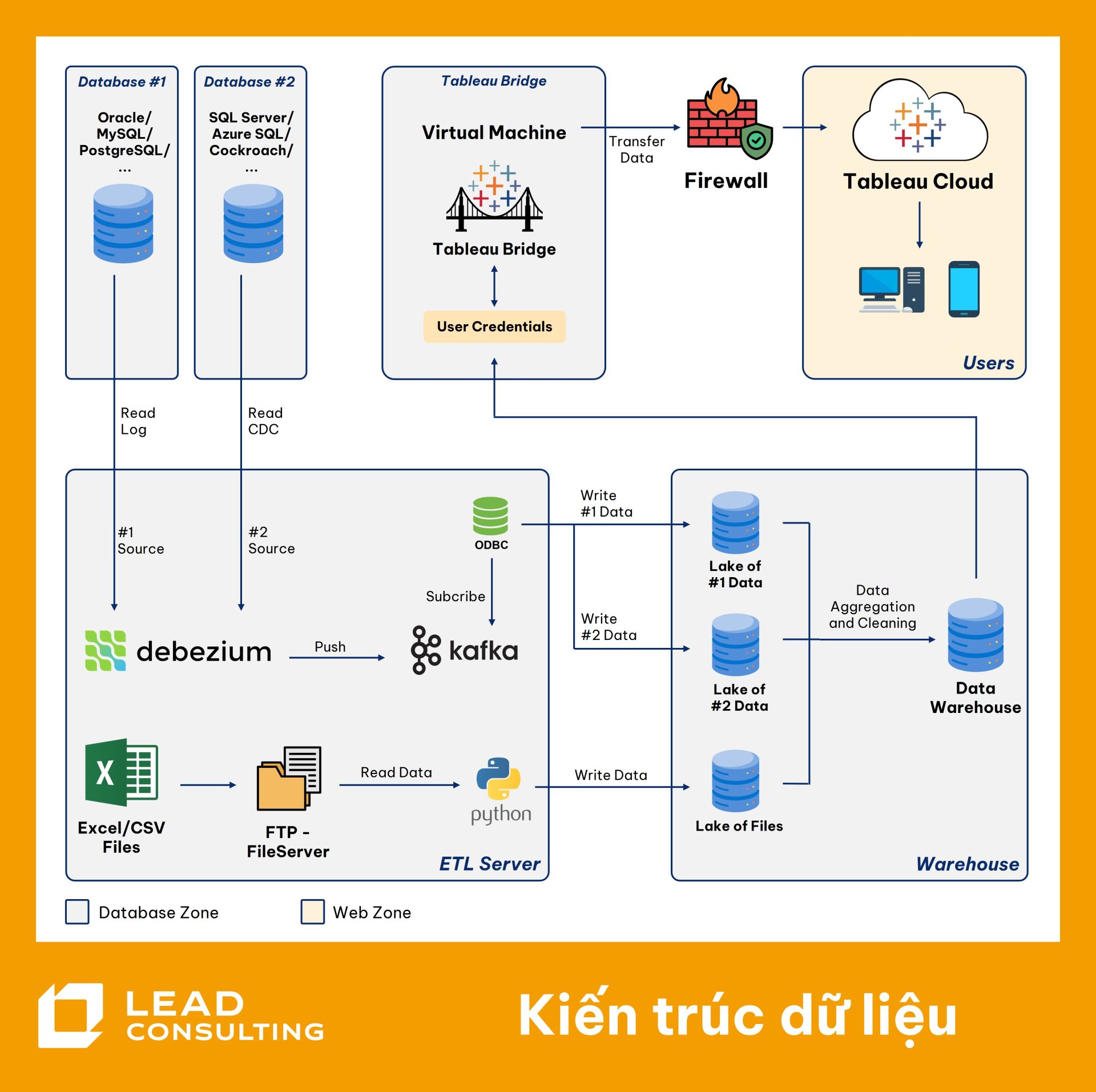
- Nguồn dữ liệu: Các nguồn dữ liệu từ Oracle/My SQL/PostgreSQL và SQL Server/AzureSQL/….
- Luồng dữ liệu: Mọi thay đổi từ các CSDL nguồn được Debezium thu thập, đẩy qua Kafka và ghi vào cơ sở dữ liệu đích là SQL Server gần như theo thời gian thực.
- Trực quan hóa: Tableau kết nối vào CSDL đích để xây dựng các dashboard phân tích vận hành.
1) Vai trò của Debezium (Extract)
- Debezium Connector đọc trực tiếp các nhật ký giao dịch (transaction/redo log) từ cơ sở dữ liệu. Phương pháp này không cần cài đặt trigger hay thay đổi ứng dụng nguồn, đảm bảo tính toàn vẹn và giảm thiểu tác động hiệu năng. Mọi thao tác (insert/update/delete) đều được chuyển đổi thành các sự kiện có cấu trúc thống nhất.
2) Dòng dữ liệu qua Kafka (Staging & Transport)
- Kafka đóng vai trò là một lớp đệm (buffer) chịu tải cao và bền bỉ. Dữ liệu từ các nguồn được tổ chức thành các “topic”, đảm bảo luồng chảy ổn định ngay cả khi lưu lượng tăng đột biến. Kiến trúc này cũng cho phép các ứng dụng khác (ví dụ: hệ thống cảnh báo, machine learning) có thể “lắng nghe” cùng dòng dữ liệu mà không ảnh hưởng đến luồng ETL chính.
3) Ghi và Chuẩn hóa dữ liệu tại Cơ sở dữ liệu đích (Transform & Load)
- Dữ liệu từ Kafka được ghi vào một khu vực trung gian (staging area) tại CSDL đích (SQL Server). Tại đây, các quy trình xử lý sẽ được áp dụng để làm sạch, chuẩn hóa (ví dụ: đồng bộ mã giao dịch, mã sản phẩm, đơn vị tính) và cấu trúc lại dữ liệu theo mô hình kho dữ liệu, sẵn sàng cho việc phân tích. Với các dữ liệu dạng file (Excel, CSV), đội ngũ Lead Consulting sử dụng Python script để tiền xử lý và nạp vào CSDL đích.
4) Kết nối và trực quan hoá trên Tableau Cloud
- Dữ liệu nằm trong mạng nội bộ của tổ chức, do đó, để đưa lên internet, cần sử dụng công cụ Tableau Bridge (được đặt phía sau tường lửa, là cầu nối giữa kho dữ liệu và Tableau Cloud) để kết nối đến các bảng dữ liệu đã được chuẩn hóa. Dữ liệu có thể được truy vấn trực tiếp (Live) hoặc trích xuất (Extract) theo lịch để tối ưu hiệu suất. Các dashboard cung cấp chỉ số vận hành như: lưu lượng giao dịch theo khung giờ, thời gian xử lý trung bình, hiệu suất hoạt động của các phòng ban chức năng, v.v.
Tham khảo và trải nghiệm các dashboard mẫu tại đây:
5) Đảm bảo chất lượng và vận hành
- Toàn bộ dữ liệu đều được giám sát chặt chẽ, cảnh báo khi có sai lệch và lưu trữ các bản ghi lỗi vào “dead-letter queue” để xử lý sau. Các quy tắc bảo mật, ẩn danh, phân quyền truy cập được áp dụng nghiêm ngặt để bảo vệ dữ liệu nhạy cảm.
Kết luận
Thông qua nghiên cứu, phân tích và triển khai thực tế, kiến trúc ETL sử dụng Debezium và Kafka đã chứng tỏ là một giải pháp hiệu quả vượt trội, giúp hợp nhất dữ liệu từ các hệ thống đa nền tảng một cách ổn định và có kiểm soát. Nền tảng này không chỉ cung cấp dữ liệu kịp thời cho các dashboard vận hành, mà còn tạo ra một hạ tầng dữ liệu linh hoạt, bền vững và sẵn sàng cho các nhu cầu mở rộng trong tương lai.
Trong môi trường hiện nay, tốc độ và sự chính xác của thông tin là yếu tố quyết định lợi thế cạnh tranh. Việc lựa chọn đúng công nghệ và kiến trúc không chỉ là một bài toán kỹ thuật, mà còn là một quyết định chiến lược. Với kinh nghiệm thực tiễn qua các dự án phức tạp, Lead Consulting tự tin đồng hành cùng doanh nghiệp không chỉ trong việc triển khai công nghệ, mà còn trong việc xây dựng chiến lược dữ liệu toàn diện.